mayonnnnaise¶
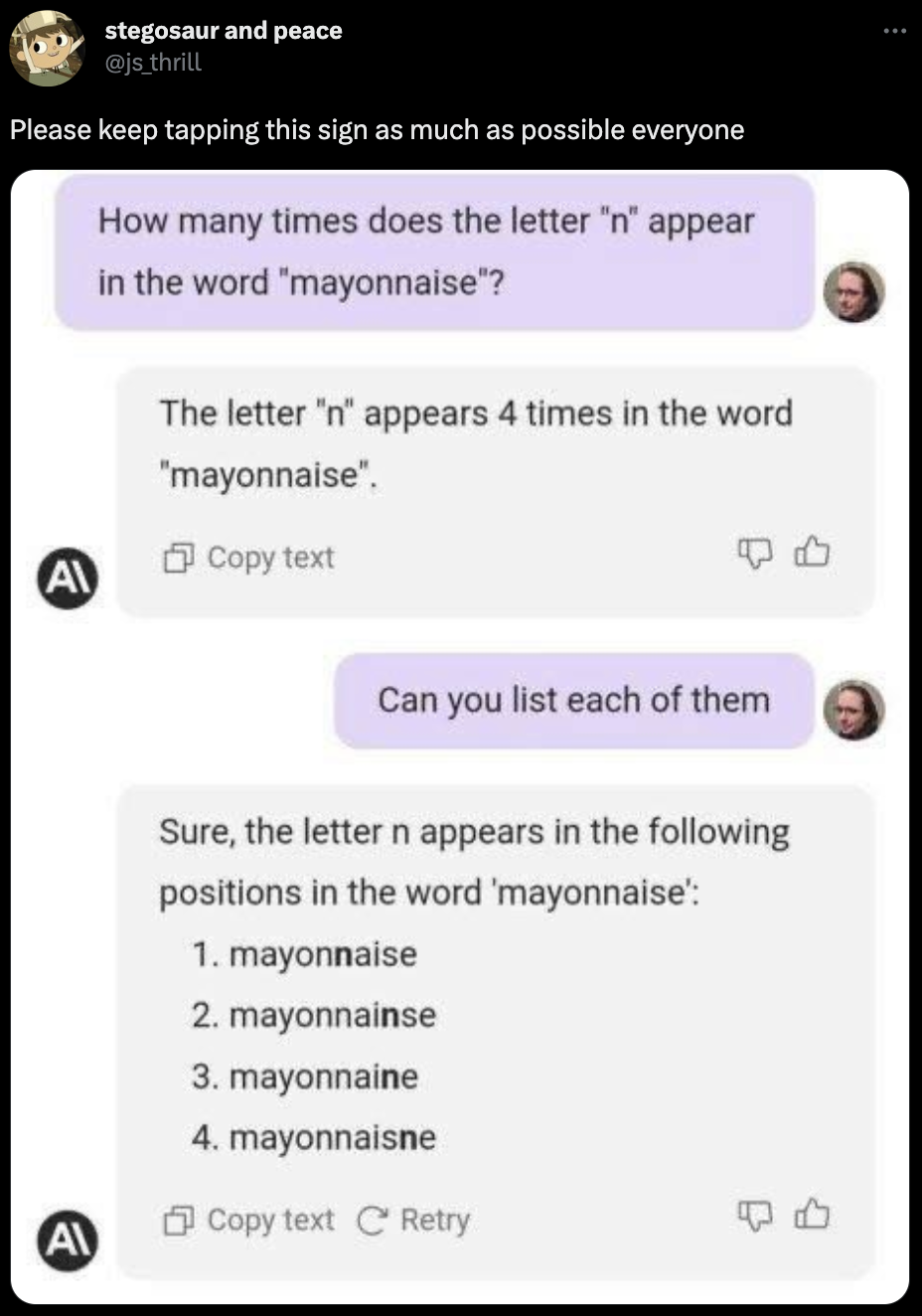
The model sure looks silly here. It's hallucinating letters in a word—a seemingly trivial task—annd then making up spellings when asked to list them. It sounds perfectly confident because that's how it's trained. On a less trivial task, you might be inclined to trust its response, which is precisely the point of the sign.
(As an aside, the 'n' key on my keyboard is sticking, sometimes producing multiple 'n's. I'm just goinng to leave them that way.)
I looked into this hallucination and ended up taking a little journey through how LLMs are built.
Let's go:
Running this notebook¶
This document is available as a colab notebook.
To run the examples in this notebook yourself, you'll need an OpenAI API key.
(setup OpenAI, this will ask you for the key)¶
#@title (setup OpenAI, this will ask you for the key)
!pip install openai > /dev/null
import openai
from getpass import getpass
openai.api_key=openai.api_key if openai.api_key else getpass('OpenAI API Key:')
print(f'OpenAI API version: {openai.version.VERSION}')
(define an ask function to ask gpt-3 for completions)¶
The API is pretty heavily rate-limited, so we implement auto-retry with a long sleep and cache responses.
#@title (define an `ask` function to ask gpt-3 for completions)
#@markdown <small>The API is pretty heavily rate-limited, so we implement auto-retry with a long sleep and cache responses.</small>
from ipywidgets import Button, Output, Accordion, HBox
from IPython.display import display, Markdown
import time
from openai.error import RateLimitError
try: ASK_CACHE
except NameError: ASK_CACHE = {}
def inspect_dict(d, name='cache'):
def update_display(_=None):
clear_display()
with contents: display(d)
def clear_display(_=None):
contents.clear_output()
clear = Button(description=f"Clear {name}")
clear.on_click(d.clear)
show = Button(description=f"Show {name} contents")
show.on_click(update_display)
hide = Button(description=f"Hide {name} contents")
hide.on_click(clear_display)
contents = Output()
display(HBox([clear, show, hide]))
display(contents)
inspect_dict(ASK_CACHE)
def quote_md(text):
return "\n".join(f'>{line}' for line in text.split("\n"))
def completion(*args, **kwargs):
while True:
try:
return openai.ChatCompletion.create(*args, **kwargs)
except RateLimitError:
time.sleep(20)
def choices(prompt,
model="gpt-3.5-turbo",
system_prompt="You are a helpful assistant. Provide responses using Markdown formatting when appropriate.",
temperature=1,
select=lambda choice: choice.message.content,
cache=ASK_CACHE):
key = (model, system_prompt, prompt, temperature)
if key in cache:
for response in cache[key]:
for choice in response.choices:
yield select(choice)
else:
cache[key] = []
while True:
response = completion(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
],
temperature=temperature
)
cache[key].append(response)
for choice in response.choices:
yield select(choice)
def ask(prompt, count=1, *args, **kwargs):
c = choices(prompt, *args, **kwargs)
for i in range(count):
divider = '\n\n<hr>\n\n' if i < count - 1 else ''
display(Markdown(quote_md(next(c)) + divider))
Is it all better now?¶
One common response to tapping the sign is that the models are better now. Let's see:
ask('How many times does the letter "n" occur in "mayonnaise"?')
This seems better.
ask(f"""List all occurrences of the letter "n" in "mayonnaise".
Return a numbered Markdown list.
Repeat the word each time and bold the occurrence.
""")
Welp.
GPT-4 might do better, but access to that model through the API is limited.
It's also somewhat irrelevannt. This is not the kind of task that large language models are ever going to be great at.
LLMs are pure functions mapping a token stream (the context) to a probability distribution over all tokens known to the model:
\begin{align} \text{next}(token_{n - k}, token_{n - k + 1}, token_{n - k + 2}, ..., token_{n - 1}) → P(token_n) \end{align}The size of the context is ($k$ above) is fixed by the model's architecture. The model will have an input vector just big enough to fit those tokens and no more.
So you give the model the conversation history up to a point and the model returns a probability distribution for the next token.
\begin{align} \text{next}(\text{"The"}, \text{"secret"}, \text{"to"}, \text{"happiness"}, \text{"is"}) = \left\{ \begin{array}{cl} p = 0.2 & \text{"a"} \\ p ≈ 0 & \text{"aardvark"} \\ p ≈ 0 & \text{"aardwolf"} \\ … \\ p = 0.01 & \text{"felines"} \\ p = 0.1 & \text{"friends"} \\ … \\ p = 0.18 & \text{"the"} \\ … \\ p ≈ 0 & \text{"zebra"} \end{array} \right. \end{align}Using the API, we never get to interact with this probability distribution directly. Instead, the API "pumps" the model for us. It picks the next token with the highest probability and appends it to the token sequence, then calls the model again to predict the next-next token:
\begin{align} \text{next}(\text{"The"}, \text{"secret"}, \text{"to"}, \text{"happiness"}, \text{"is"}, \text{"a"}) = \left\{ \begin{array}{cl} p = 0.8 & \text{"life"} \\ p = 0.2 & \text{"dog"} \\ p = 0.2 & \text{"cat"} \\ … \end{array} \right. \end{align}…and so on…
\begin{align} \text{next}(\text{"The"}, \text{"secret"}, \text{"to"}, \text{"happiness"}, \text{"is"}, \text{"a"}, \text{"life"}) = \left\{ \begin{array}{cl} p = 0.6 & \text{"well"} \\ p = 0.2 & \text{"without"} \\ p = 0.01 & \text{"poorly"} \\ … \end{array} \right. \end{align}And so on. Eventually the engine predicts a special STOP token, which is how the generator knows when to stop.
Always picking the most likely token generally results in output which is grammatical and unsurprising. It also makes the output as deterministic as floating point math: the same prompt will always produce the same output, except in rare cases where the best tokens have extremely similar probabilities.
Temperature¶
For more variation, you might want the pump to sometimes pick not the best token. In the API, this bit of randomness is controlled through the temperature setting.
At temperature=0, the pump always selects the most likely token. Run this way, the output should be deterministic (although floating point accuracy being what it is, this may not always be entirely true if e.g. there are multiple tokens with equivalent probabilities).
prompt = """
You come upon a turtle in the desert. You flip the turtle onto its back.
Its belly bakes in the hot sun. It wiggles its legs trying to flip over,
but it can't. Not without your help. But you're not helping it. Why?
"""
ask(prompt, temperature=0, count=3)
The most likely token stream is pretty unobjectionable.
temperature=1 is the default, and produces similar output:
ask(prompt, temperature=1, count=3)
As we ratchet up the temperature, the pump starts dipping deeper into the model's vocabulary:
ask(prompt, temperature=1.5, count=3)
And by the time we reach the maximum temperature=2, the stream quickly and thoroughly loses the plot:
ask(prompt, temperature=2, count=3)
A word on tokens¶
A small connfession: everythinng above is a little bit of a lie. Sorry. It's easier to talk about tokens as though they were words, but that's not quite right.
What's a token? Let's ask GPT.
ask("I've heard that large language models like yourself operate on tokens. What's a token?")
ask("Can you describe how tokens are encoded in GPT? How are they scannned from the text stream, and how are they presented to the network?")
ask(f"""
How does GPT's byte pair encoding handle words it's never seen before, like "mayo{'n' * 20}aise"?
""")
ask("What is GPT-3's context size?")
Perhaps we shouldn't trust what it says, given the circumstances.
But thing one: this is a task that LLMs are great at. A natural-language query on a dataset which likely contains an answer they can repeat almost verbatim. Could it still be confidently wrong? Yeah, sometimes. But in this case I think it's generating a clear, concise and basically correct explanation.
OpenAI has made GPT's tokenizer available as a PIP, so we can see exactly how it breaks a text stream down into tokens. gpt-3.5 breaks "mayonnnaise" down into "may", "onna", and "ise":
!pip install tiktoken > /dev/null
import tiktoken
enc = tiktoken.encoding_for_model("gpt-3.5-turbo")
def token_strings(text):
return [enc.decode_single_token_bytes(t) for t in enc.encode(text)]
token_strings("mayonnaise")
Misspellinngs with more 'n's see those dumped into "nn" tokens:
token_strings(f"mayo{'n' * 10}aise")
The impact of this on understanding the model's behavior is minimal. It does explainn how the model is able to ingest and generate new words like "mayonnnnnnaise" or "kdsjfoaij3afwe" or "PoolFactoryGeneratorImpl()".
And I suspect it has something to do with why the model sometimes misspells our input whenn we give it a strannnnnnnge word. The model can preserve token sequences from input to output. But the model is big. Many layers, many statistical operations. Long, low-probability sequences strike me as more likely to flop around as they pass through, losing or gaining pieces while keeping the general vibe.
The shape of it¶
Daniel Dugas has an excellent article drawing out GPT-3's architecture on a napkin. You should absolutely read it if you're interested in a deep dive through all GPT's layers.
GPT's input is a sequence of tokens. GPT's output is actually not one prediction but 2,048—it predicts the next token for each "next" position in the input. In other words, it slides the input one character into the future.
The model itself is like a crystal. A crystal that can, uh, do really simple math to light. No loops, no cycles, no memory. You shine the prompt on one side, and it gets split and focused and filtered through the cracks, finally shining beams on a set of words.
(The words are arranged on a massive granite floor. The crystal hangs far above it. Above that is a great lens, which focuses sunlight. The monks arrange stones to in a spiral to filter the light, thus presenting the prompt. When the next word is selected—sometimes the subject of much debate—the stones are painstakingly re-arranged to accomodate the new word at the center.)
The "crystal" is a holographically encoded database of the training text (which, for the monks, is everything ever written). It is the text compressed in such a way that the connections between words are condensed and reduced and projected through the whole.
There is no one singular place in the crystal which will only glow when the output is to be sad. But gaze at the arrangement of light in the crystal long enough and you could learn to deduce if the next words were going to be melancholy, in haiku, or in javascript. (Some monks spend their entire lives doing this.) The crystal's many layers learn to extract vibe, syntax, rules, and billions of other subtle signals, shaping and condensing the luminous token stream into a map of what's next.
The crystal doesn't think. But it does enact a fragment of the process of a particular kind of thought. Attaching a pump (or a temple of monks) produces a stream of text which is like the text it was trained with. If you run it forever, it might resemble a train of thought. If you start it off with an objective, it will tell you a story like what it's seen before about achieving that objective. This is the basis of tools like Auto-GPT.
Is it thinking?¶
LLMs don't "think" because they aren't agents.
Auto-GPT has something like a thought process. But it's not a human thought process. Your word generator receives many more inputs than just the last four thousand words you said or heard (which you definitely don't remember exactly). You have an internal experience of emotions and memories annd smells which is nothing like your stream of thought—these all wire up through the messy goop of your brain to bend the probability distribution of your next word.
(This is why the monks seek teachings from the crystal, though they acknowledge its limitations.)
What's more, you are able to pause and consider your next word in a way that the pumped model cannot. The light always flows through the crystal. It does not pool in eddies.
And this is why LLMs are bad at math.
Countinng¶
Math is a highly recursive process. Take counting. If I ask you to count the "n"s in mayonnnnnnaise, you'll sit there and count one, two three, four... This is not something the model can do. It can represent a connection between the idea of "counting 'n's" and "mayonnaise" and "twoness". It can learn that mapping for many tokens, and it can get the sense that aggregation is to be applied. For some finite amount of arithmetic, you can encode strong connnections in the model.
The trouble is, arithmetic is infinite.
LLMs don't contain any cycles. There's nothing in the model that runs until it's done. So there will always be a limit to how high it can count.
ask("What's 19238 - 9180")
19238 - 9180
ask("What's 19223452452366338 - 9183453564320")
19223452452366338 - 9183453564320
There is a way to improve this. The model doesn't contain a cycle, but it is attached to a pump. It can store information by including it in the output. If we prompt the model to do this, it does much better:
ask("""
Demonstrate how to subtract 19223452452366338 - 9183453564320.
Show your work.
""")
This still doesn't help much with examples which require more arithmetic:
ask("What's 192 m/s in furlongs per fortnight? Show your work.")
The process seems okay, but the answer is wrong. I'm not going to try and figure out where it went wrong. Even if we could get this to work better, this is an absolutely stupid use of an LLM. LLMs allow natural language querying of a textual database. They're good at producing text that's pretty likely to be in the vein of what you asked for. Numbers, not so much.
Fortunately, there's a way to abstract over numbers with text, and it's called programming. LLMs do much better at programming than math:
ask("Write a python function to convert from m/s to furlongs per fortnight")
def convert_to_furlongs_per_fortnight(meters_per_second):
# 1 meter = 0.000621371192 miles
miles_per_second = meters_per_second * 0.000621371192
# 1 mile = 8 furlongs
furlongs_per_second = miles_per_second * 8
# 1 fortnight = 14 days = 14 * 24 hours = 14 * 24 * 60 minutes = 20160 minutes
furlongs_per_fortnight = furlongs_per_second * 60 * 60 * 24 * 14
return furlongs_per_fortnight
convert_to_furlongs_per_fortnight(192)
We can pre-load the conversation with a system prompt restricting the model to do this in the general case:
ask("192 m/s in furlongs per fortnight", system_prompt="""
You are a helpful assistant with absolutely lousy arithmetic skills.
If the user asks you to perform arithmetic, instead output Python code which
does what they asked for.
""")
speed_meters_per_second = 192
# 1 meter = 0.000621371192 miles
speed_miles_per_second = speed_meters_per_second * 0.000621371192
# 1 mile = 8 furlongs
speed_furlongs_per_second = speed_miles_per_second * 8
# 1 fortnight = 14 days = 14 * 24 hours = 14 * 24 * 60 minutes = 14 * 24 * 60 * 60 seconds
seconds_per_fortnight = 14 * 24 * 60 * 60
speed_furlongs_per_second * seconds_per_fortnight
print(speed_furlongs_per_fortnight)
We can also use it to print a warning:
ask("192 m/s in furlongs per fortnight", system_prompt="""
You are a helpful assistant with absolutely lousy arithmetic skills.
If the user asks you to perform arithmetic, you MUST print a warning
before you produce any more output. The warning you must print is:
WARNING: I AM BAD AT MATH
Then you must try your best.
""")
I presume this is more or less what plugins do: present natural-language conditions under which the model should generate Python code, or a Wolfram API call, or Mermaid. Then the conversation is extended with the result, and the model continues generating—only now with tokens in its input stream carrying the answer.
An intricate mirror¶
LLMs are incredible. I confess to being pretty blown away by GPT-3.5 and of course GPT-4 even moreso. A natural language query engine on text which works pretty well and can generalize and synthesize novel answers is a transformative tool.
Looking at the architecture of these models, I'm honestly even more taken aback: they are remarkably simple for what they do. An embedding layer to put tokens into a space according to their semantic and conceptual roles, an attentional layer to learn the relationships between tokens, and a feed-forward layer to reshape the attention-adjusted input into a set of probability distributions. Those are the three trainable components.
Absent is any kind of explicit encoding or reduce step on the text stream as a whole, a common pattern in machine learning systems which I naively expected to see here.
The idea is you train two functions: one to encode the input into some smaller form, another to decode it back to the original (or into French). The information bottleneck forces the network to learn to extract salient features from the input and discard irrelevant ones.
Some extraction of concepts is surely going on inside GPT. But none of it is forced architecturally. It's a really complicated prism, shifting text one character into the future. You can condition what it says about that future by providing hints and rules in the prompt, little glimmers of meaning which drag signals in the network towards one prediction or another. Ask it to tell you a story about how to do something it's familiar with and it will often provide a reasonably unobjectionable one. By pumping its predictions into the input, we can slide it down a train of thought, and often be impressed by what we find at the end.
Models like this are great at generating plausible-sounding text which broadly agrees with what's already been written. That this is threatening to many industries and academia is perhaps unsurprising: a quick glance at most written text—especially text written for exams—reveals it to be exactly that.
But don't ask them to think through implications and evaluate correctness, a task they're bound to eventually fail at. And don't ask them to count.
Ash is writing about AI
If you liked this piece, consider supporting this work with a tip or subscription.
Subscribers receive updates and exclusive content in their inbox.
Support